【rest-framework】
这是一个基于django才能发挥作用的组件,专门用于构造API的。
说到API,之前在其他项目中我也做过一些小API,不过那些都是玩票性质,结构十分简单而且要求的设计强度并不高,要求的请求方式也不太规范。要想做一个规范的健壮的API,最好的办法果然还是站在巨人的肩膀上,学习一些现成组件的使用方法来构建自己的API最为保险简单。
下面就来从我的角度简单说说rest-framework这个框架如何使用。
本篇主要参考了 ,以及这个系列的翻译(、、、剩余作者还在继续翻译中)。
安装可以使用pip install djangorestframework
■ 何为RESTful的API
首先有必要了解一下什么是REST,REST的全称是Representational State Transfer,是一种软件设计和架构的风格。目的在于提升开发的效率,增加系统的可用性和可维护性。可以把它看成是一种在开发网络应用过程中产生的最佳实践。遵循REST风格的接口就是RESTful的API。这种API,考虑到网络中客户端和服务端的交互,其本质是CURD(Create,Update,Read,Delete)等各种操作和数据交互,将各种类型的数据交互和具象的HTTP方法联系起来,形成一套API的设计规则:
GET /resource 获取所有resource对象的列表
GET /resource/ID 获取指定resource对象
POST /resource 根据POST数据中的参数新建一个resource对象
PUT /resource/ID 全量更新指定的一个resource对象
PATCH /resource/ID 部分更新指定的一个resource对象
DELETE /resource/ID 删除一个指定的resource对象
有了上面这套规范,我们当然可以自己实现一个API了,不过工作量还是偏大一些。rest_framework就是一个很好的遵循了这个规范的框架,我们只需要编写相对少的代码就可以得到一个功能健全的API了。
■ rest_framework的基本使用
rest_framework框架是在django中使用的,为了说明方便,我们假设在一个django项目中我们startapp album这个APP,然后在它的models.py文件中定义了如下一个“专辑”的模型:
class Album(models.Model): id = models.AutoField(primary_key=True) album_name = models.CharField(max_length=80) artist = models.CharField(max_length=100) def __unicode__(self): return '%s' % self.album_name
我们暂时先定义这个简单的模型,不涉及任何复杂关系。
■ 序列化器
然后我们先来说说序列化器这个东西。在rest_framework中,序列化器是一个位于客户端和后台之间的中间层。这个中间层一个最基本的作用就是接受前端JSON字符串转化为后台python可以识别的对象;从后台获取python对象然后转化为给前端的JSON格式字符串。当然如果它仅仅是这个作用的话那用json.dumps和json.loads差不多了。一个亮点在于序列化器可以定义一些字段,让进出的数据可以“一个萝卜一个坑”地填入序列化器,从而就可以方便地进行格式转化,顺便还可以做做数据校验这种工作。序列化器的另一个方便之处在于它可以和django的模型层进行互动,从而大幅度减少了编码量。下面我们来看看具体的序列化器
序列化器的类在rest_framework.serializers中,最基本的一个序列化器类是Serializer。
我们通过继承Serializer类定义自己的序列化器类。通常在类中需要指出本序列化器所有需要进行处理的字段名和字段类型,看起来有点像在定义一个Model或者一个Form。
class AlbumSerializer(serializers.Serializer): id = serializers.IntegerField() album_name = serializers.CharField(max_length=80) artist = serializers.CharField(max_length=100)
由于序列化器只是一个中间层,用于转换信息用,所以对于字段的条件校验可以设置得不那么严格。比如serializer.IntergerField()并不能添加primary_key属性,因为序列化根本不会管主键相关的逻辑,是否主键冲突或者怎么样都是最终存储的时候ORM会帮我们看的。
接下来我们演示如何使用序列化器进行序列化作业:
# 创建一条测试用的记录album = (id=1,album_name='soundtrack',artist='oreimo') # 用序列化器序列化对象,获得序列化后的对象serialized_album = AlbumSerializer(album)# 将序列化的对象转换成JSON格式from rest_framework.renderers import JSONRendererJSONRenderer().render(serialized_album.data)
序列化器接收单个ORM对象,或者一个QuerySet对象,此时需要加上many=True这样一个序列化参数。而其返回的serialized_album即所谓的“序列化后的对象”,有很多属性。其中最重要的是data属性,它是一个ReturnedDict类型(一种字典的亚种,当进行单个的序列化时)或者一个Orderdict构成的列表(当进行QuerySet的序列化时)。这些内容可以被JSON化,这里没有直接使用json模块来JSON化,而是使用了rest_framework自带的JSONRenderer类来进行JSON化处理。除了data,这类“被序列化后的ORM对象”还有诸如errors,instance,is_valid等属性和方法,这里暂时都还用不到,后面继续说。
除了序列化,序列化器还可以做的就是反序列化:
raw = '{"id":"1","album_name":"soundtrack","artist":"oreimo"}'from django.utils.six import BytesIOfrom rest_framework.parsers import JSONParserstreamed = BytesIO(raw)jsoned = JSONParser.parse(streamed)# 获得到预序列化对象,这个过程一般不出错predump = AlbumSerializer(data=jsoned)# 校验此对象是否符合要求,比如raw是不是标准的JSON格式,内容中有无不符合定义的字段等predump.is_valid()# 如果上句返回了True,那么可以查看被验证是正确的数据,否则可以查看验证不通过的具体错误信息predump.validated_datapredump.errors 其实可以看到,序列化器并没有参加“反序列化”工作,那些事让BytesIO和JSONParser做掉了,而这里序列化器所做的,无非是利用其验证功能,进行了反序列化数据的正确性验证。只有当验证通过(is_valid方法返回True),才可以调用validated_data属性。这个属性就是Python内部的对象,可以用来进行一些Python内部即web后台的操作了。相反,如果验证没通过,那么可以看errors里面的具体错误信息。errors也是一个符合JSON规范的对象。is_valid在被调用的时候可以传入raise_exception=True参数,从而使得验证失败时直接抛出错误,返回400应答。
上面验证过程的is_valid方法是一刀切的,并且验证规则有限。如果需要自己进行验证逻辑的指定,那么可以在序列化器类中实现validate方法以进行object层面的数据验证。此方法接受一个参数data(理想情况应该是一个字典或列表)表示进行validate的时候,整个序列化器中的数据。如果验证通过,则方法返回值应该是一个合法的和原值类似的结构;若验证不通过那么需要raise起serializer.ValidationError。此外Serializer类中定义class Meta也可以进行一些object层面的验证。具体不说了,可以差文档。
进一步的如果相对单个单个字段的验证,并且自己规定验证逻辑,那么可以在序列化器类中定义名为validate_<field_name>的方法,field_name是你自己定义的字段名,这个方法接受一个参数value,代表进行validate时当前这个字段的值。对于验证成功与否和object层面的验证validate方法类似。对于单字段的验证,还可以通过在Serializer类声明字段的时候指定validators=[xxx,yyy...],xxx和yyy都是定义好的函数名,
对于反序列化得到的数据,我们可能希望将其保存成一个ORM对象。此时序列化器对象提供了save方法,比如predump.save()返回的就可以是一个实例。但是目前直接调用会报错,因为save方法的调用前提条件是要实现类中的create和update方法:
def create(self, validated_data): return Student(**validated_data) def update(self, instance, validated_data): instance.id = validated_data.get('id',instance.id) instance.name = validated_data.get('name',instance.name) instance.phone = validated_data.get('phone',instance.phone) instance.comment = validated_data.get('comment',instance.comment) instance.save() return instance 这是在StudentSerailizer类中实现的两个方法,create方法很简单,就是讲传入的字典分散入参,创建一个对象返回。update方法略复杂一些,要把所有属性都安装上面的样子写出来。这主要是考虑到validated_data不全量的情况。即update时可能validated_data并不是全量信息,可能只提供了部分字段。,此时就要保证其余字段不被这次update所影响。那么create方法和update方法(全量和部分)都是在什么情况下被调用的呢?
首先这两个方法都是serializer对象调用save方法时使用。而这个serializer对象得来时,可能通过这几种方法得来:
StudentSerializer(data=data) data是一个合法的Python结构比如一个字典,此时要求其实全字段的字典。这样得到的serializer对象调用save时相当于执行create方法。
StudentSerializer(student,data=data) 还可以这样得到一个serializer对象。student是一个既存的Student类的ORM对象。此时调用update方法。传入的data字典,如果是全字段字典,那么自然就是全字段更新,否则就是部分字段更新。
需要注意的是serializer对象的save方法可不是ORM对象的save方法,它的save只是将字典中的数据充入到一个ORM对象中,而后者的save则是将ORM中的数据落地到数据库中。
■ ModelSerializer,更加方便的序列化器
(这部分内容更多的扩展写在了下面包含关系的序列化器一节中)
继承Serializer虽然可以实现一个序列化器,但是编码量仍然比较多,因为还是要一个个手工输入字段以及字段相关性质。更方便的序列化器是ModelSerializer。这个就是之前说到的可以和django模型层进行互动的序列化器。比如针对上面这个模型我们可以设计这么一个序列化器:
#-*- coding:utf-8 -*-from rest_framework import serializersfrom album.models import Albumclass AlbumSerializer(serializers.ModelSerializer): class Meta: model = Album fields = ('album_name','artist') 通常序列化器是写在项目主目录下的serializers.py文件中。可以看到,通过在序列化器类中定义Meta子类,可以指定这个序列化器和哪个模型关联,并且指出引用模型类的哪些字段。如果fields参数写'__all__'的话那么就是引用所有字段了。
如果想要除外某些字段可以设置exclude属性比如exclue = ('a',),类似的,如果想要设置某些字段的只读特征(当视图update这些字段的时候会被拒绝,create的时候也不需要提供这些字段)
■ 视图设置
在写完序列化器之后再看后台的 路由设置 和 视图设置。首先来说说视图设置。在rest_framework框架下的API视图有两种实现方式。一种是基于函数的,另一种基于类。基于函数的实现方式用到了rest_framework.decorators中的api_view装饰器。通过为一个函数加上 类似于 @api_view(['GET','POST'])的装饰器可以将这个函数作为API的视图函数。参数是和flask框架类似的,指出了该函数支持的方法类型。另外下面的函数应该带有request这个参数。基于函数的视图设置方法虽然和django原生的很像,不过有些僵硬的是它把本来应该有机一体的函数分成了好几块,不太好。
另一种基于类的视图是我重点想说的。这个类也可以写在views.py中,其继承自rest_framework.views.APIView这个类,在类中,应该要实现get,post等方法,并且给出相应的回应。比如像这样的一个类:
# -*- coding: utf-8 -*-from __future__ import unicode_literalsfrom rest_framework.views import APIViewfrom rest_framework.response import Responsefrom albumtest.serializers import AlbumSerializerfrom rest_framework import statusfrom models import Album# Create your views here.class AlbumList(APIView): def get(self,request,format=None): serializer = AlbumSerializer(Album.objects.all(),many=True) data = serializer.data return Response(data,status=status.HTTP_200_OK) def post(self,request,format=None): serializer = AlbumSerializer(request.data) if serializer.is_valid(): serializer.save() return Response(serializer.data,status=status.HTTP_200_OK) return Response(serializer.errors,status=status.HTTP_400_BAD_REQUEST)
基于RESTful的思想,其实对于一个模型,我们可以将各个操作泾渭分明地分别写在两个类里,分别是AlbumList(就是上面这个)和AlbumDetail。前者用于访问/resource的获取全对象和新增对象两个操作;后者用于访问/resource/ID的查改删单个对象的操作。更加详细的类在下面给出,我们先进入get方法看下具体代码。get方法接受了一个request参数和format参数。实例化AlbumSerializer这个序列化器用到的是一个名为instance的参数,可以接受单个模型实例,也可以接受一个queryset,当参数是一个集合的时候应该加上many=True参数来保证有效的序列化。
实例化之后的序列化器有很多属性,最常用的就是data属性,表示该序列化器对象序列化出的内容(字符串)是什么,然后通过rest_framework框架提供的Response类返回结果字符串。另外status参数也是必要的,rest_framework也提供了status这个类,其中有一些常量供我们使用。
再来看post方法,post方法是从客户端接受数据解析后传给后台的,这样子的话就用到了request参数中的data属性。注意这个request参数有别于一般django视图函数中的request参数,总之我们调用其data属性就可以获得这个POST请求的参数了。之后是is_valid方法,这个方法是serializer自带的一个方法,可以根据定义时字段的控制来校验得到的参数格式等是否正确。如果不正确,无法合法落库,自然需要返回错误信息。此时调用了序列化器的另一个属性errors,它包含的就是序列化过程中发生的错误信息了。
● 路由设置
rest_framework也为我们提供了方便的路由设置的办法(通过rest_framework.routers),由于路由设置即便是手写也还好不过几行代码而已,所以这里暂时用手动设置的办法来设置路由。
这次我们将路由设置在主目录下的urls.py中,这里已经预设了/admin的路由。我们加上两条:
from django.conf.urls import url,includefrom django.contrib import adminfrom album import viewsurlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^albums/',views.AlbumList.as_view()), url(r'api-auth',include('rest_framework.urls'))]
可以看到,之前定义的视图类,我们通过调用as_views()方法来使其转换成可以被django的url方法接受的参数。前面配置的路径是/albums,也就是说对于Album这个模型,我们基于RESTful思想的API设计中的那个resource就是albums了。也就是说GET访问/albums可以获取所有albums的列表这样子。
第二条是一个rest_framework对于API验证的支持。加上这项配置之后,我们可以对访问API的当前用户(匿名或者普通或者超级用户等等)做出感知并且给出相关的回应。这方面内容在后面细讲。
为了让以上一大票rest_framework框架相关的内容生效,也别完了在settings.py的INSTALLED_APPS中加上'rest_framework'。
OK,至此这个API已经可以正常运行了,别忘了同步数据库信息等django通用步骤。然后我们通过浏览器访问目标地址的/albums路径可以看到这样一个界面;
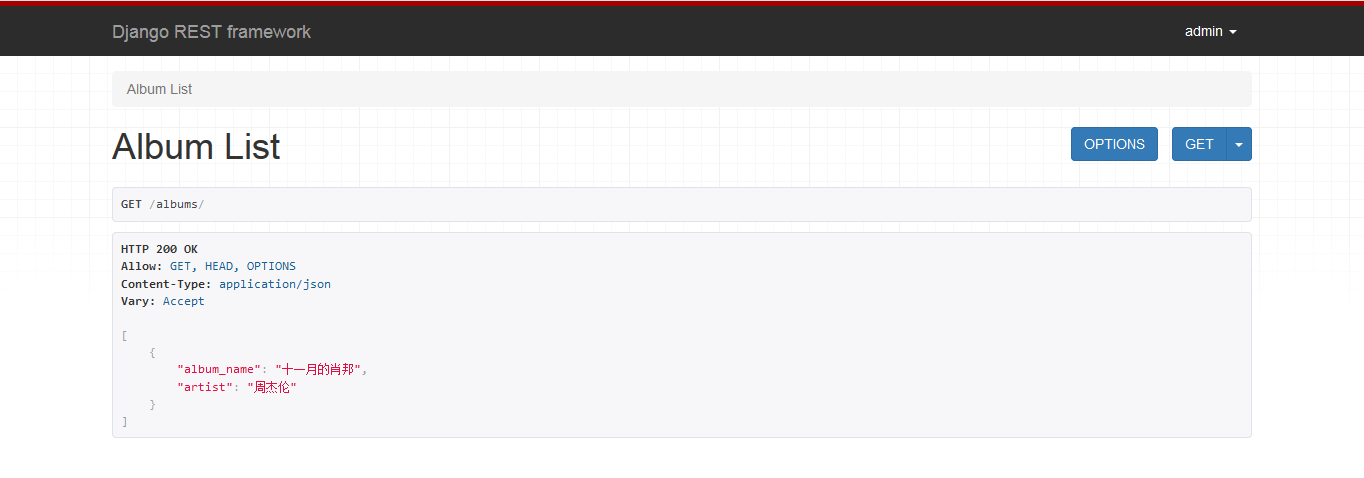
看到的是个界面而不是一个JSON串,这是因为通过浏览器访问时,在请求头中的Accept字段默认是html(这类似于javascript发起的ajax请求中的dataType字段写什么),如果一个请求的Accept指明是json或者是默认值的话,那么就会返回json串了。
顺便一提,这个界面是rest_framework为了方便开发和调试加入进来的,确实很好用。但是在生产上这个界面肯定是要关掉的。具体怎么关我还要研究下。。。
● 关于AlbumDetail类
刚才提到了AlbumList类是针对访问/album的,那针对/album/<ID>的那个类给出如下:
class AlbumDetail(APIView): def get_object(self,pk): try: return Album.objects.get(id__exact=pk) except Album.DoesNotExist,e: raise Http404 def get(self,request,pk,format=None): album = self.get_object(pk) serializer = AlbumSerializer(album) return Response(serializer.data) def put(self,request,pk,format=None): album = self.get_object(pk) serializer = AlbumSerializer(album,data=request.data) if serializer.is_valid(): serializer.save() return Response(serializer.data,status=status.HTTP_200_OK) return Response(serializer.errors,status=status.HTTP_400_BAD_REQUEST) def delete(self,request,pk,format=None): album = self.get_object(pk) album.delete() # 这个delete方法就是django模型对象自带的那个,和rest_framework框架无关 return Response(status=status.HTTP_204_NO_CONTENT)
需要注意几个点,get_object方法不是rest_framework要求的,但是有了这个方法的话可以让整体的耦合度升高。除了这个方法之外其余所有方法都还有参数pk,其意思是primary_key,即这个模型对象的主键,也是rest_framework从请求url中解析出来的那个标识符。一般情况下是个unicode的字符串。在get_object中,之前的范文中写的是get(pk),这会报错,稳妥一点还是加上id__exact=pk吧。
其他所有方法也都是用到了get_object,另外的到没什么好说的了,反正都是类似的。
然后记得在urls.py中的urlpatterns中加上这条:
url(r'^album/(?P[0-9]+)/$', views.AlbumDetail.as_view())
需注意,之前如果r'^album/'最后没加$,要加上,否则/album/1请求有可能会路由到那边去。然后重启应用就可以访问了。可以尝试用PUT方法改变一个Album对象或者用DELETE方法删除一个对象。
关于正则url规则中pk的命名:一般而言这个变量名是可以自己控制的,只要将相关视图方法中的参数也改名即可。但是在继承封装度比较高的视图类时,最好不要改,因为默认是识别pk这个变量名的。
■ 请求与响应
在上面的基本使用的说明之后,我们再来看下rest_framework这个框架的各个细节部分。首先是在这个框架下的请求与响应。
在基于类的视图中,我们定义了各个API方法,在方法的参数中带有request参数作为一个请求的映射。实际上这个request是一个继承自HttpRequest的东西,它更加适应RESTful风格的API。其核心要素时request.data属性,它代表了一般视图中request.POST,requset.PUT,request.PATCH三种可能的数据结构。
在API方法中我们最终都回复了一个Response对象(即便是DELETE方法这种无需回复信息的请求我们也回复了204),
另外在上面给出的,基于类的视图中,其实已经可以感觉到,通用性是蛮大的。把Album换成另外一个模型,似乎这些代码也不用怎么改就能直接用。这就说明代码还有更精简的空间。实际上,这种分成List和Detail两个类的模式rest_framework确实也给出了这种模式方便的实现方式。名曰泛类实现(generic class):
from rest_framework import genericsfrom serializers import AlbumSerializerfrom models import Albumclass AlbumList(generics.ListCreateAPIView): queryset = Album.objects.all() serializer_class = AlbumSerializerclass AlbumDetail(generics.RetrieveUpdateDestroyAPIView): queryset = Album.objects.all() serializer_class = AlbumSerializer
这里使用泛类实现的基于类的视图,和上面自己一个个写API方法,在使用上是一模一样的。不过泛类大大减小了编码量。
■ 包含关系的序列化器
刚才我们给出的模型十分简单和单一,没有涉及到关系。自然,就会想当涉及到关系时,rest_framework是如何处理关系的。为了说明关系,我们改造了一下现有的Album模型并新增了Track模型:
class Album(models.Model): id = models.AutoField(primary_key=True) album_name = models.CharField(max_length=80) artist = models.CharField(max_length=100) def __unicode__(self): return '%s' % self.album_nameclass Track(models.Model): album = models.ForeignKey(Album,on_delete=models.CASCADE,related_name='tracks') order = models.IntegerField() title = models.CharField(max_length=100) duration = models.IntegerField() class Meta: unique_together = ('album','order') ordering = ['album'] def __unicode__(self): return '
可以看到Track中有album字段,是个Album模型的外键连接。并且设置了反向引用时的引用名是tracks(重要!)
在这种时候,理想情况下,我们GET /albums这个API时,返回的结果中最好有一个tracks字段,其包含了一些和这个album对象相关的track的信息。要达到这种效果,最关键的是要改造序列化器。
rest_framework中有一个relations.py文件,里面包含了我们可能在序列化器中用到的很多关于关系操作的字段。比如我们将AlbumSerializer这个序列化器改造成这样子:
class AlbumSerializer(serializers.ModelSerialzier): tracks = serailizers.StringRelatedField(many=True) class Meta: model = Album fields = ('album_name','artist','tracks')
虽然继承了ModelSerializer,但是还是重写了tracks这个字段,将其指定为一个StringRelatedField,通过这样的改造,得到的某一个album的tracks字段就是一个字符串的列表,每一个成员都是track模型调用__unicode__方法返回的结果。
当然除了StringRelatedField之外,还有很多其他的,比如
PrimaryKeyRelatedField 得出的列表是相关模型的id组成的列表
HyperlinkedRelatedField 返回的列表是相关模型详细信息的url的列表,需要指定view_name,这个view_name应该和urls.py中/resource/ID这个路由指出的name一致,这样才可生成正确的url列表
SlugRelatedField 上述返回的列表内容的字段都是这个Field指定好的(主键或者相应的url等),而这个SlugRelatedField可以让我们自己指定,只要在参数中写上slug_field='字段名'即可。如SlugRelatedField(many=True,read_only=True,slug_field='title')时,返回的tracks的列表中就是各个tracks的title字段的值了。
类似功能的Field也还有一些,值得注意的是,除了最上面的StringRelatedField,其他所有Field都要加上queryset参数或置参数read_only=True。这主要是因为当我们为API添加关系之后,如果我们要通过一个模型的API去修改另一个模型的值时,rest_framework框架需要queryset去校验数据的合法性。比如这里我们可以queryset=Track.objects.all(),不过这么搞不是很符合RESTful思想(修改一个模型应该在这个模型自己的API中进行),所以一般设置成read_only会比较好。但是如果涉及到新增,那么就必须设置一个queryset了,否则将无法POST争取的数据用于新增。
● 返回完整关系--序列化器之间互相调用
上面不论是用哪个Field,返回的tracks字段的列表中都是相关track的部分信息,有没有办法返回完整的信息呢?答案是不用serializers提供的Field,而是直接使用自己的Serializer来实现。
首先改造序列化器:
from rest_framework import serializersfrom album.models import Album,Trackclass TrackSerializer(serializers.ModelSerializer): class Meta: model = Track fields = ('order','title','duration')class AlbumSerializer(serializers.ModelSerializer): # tracks = serializers.StringRelatedField(many=True) # tracks = serializers.PrimaryKeyRelatedField(many=True,queryset=Track.objects.all()) 这些是上面提到的Field,顺便做个示例,就不删了 # tracks = serializers.SlugRelatedField(many=True,read_only=True,slug_field='title') tracks = TrackSerializer(many=True,read_only=True) class Meta: model = Album fields = ('album_name','artist','tracks') tracks字段直接被定义成了目标模型的序列化器,由于类之间的引用关系的规定,这导致TrackSerializer必须定义在AlbumSerializer之前。这样子再去调用时,tracks字段就是一个字典的列表了,每一个字典带的就是每个track的order,title,duration字段的信息。
● 可写的完整关系
通常默认情况下,上面这种直接调用别的Serializer作为一个RelatedField而形成的关系是只读的。比如上面例子中,我们可以GET到某个Album中的一个Track对象的列表,但是在POST时不允许你也带这么一个Track对象的列表,后台不会识别并且将这些tracks作为新纪录增加进数据库。要实现可写的完整关系,需要在AlbumSerializer这样一个序列化器类中重载create方法比如:
class TrackSerializer(serializers.ModelSerializer): class Meta: model = Track fields = ('order', 'title', 'duration')class AlbumSerializer(serializers.ModelSerializer): tracks = TrackSerializer(many=True) class Meta: model = Album fields = ('album_name', 'artist', 'tracks') def create(self, validated_data): tracks_data = validated_data.pop('tracks') album = Album.objects.create(**validated_data) for track_data in tracks_data: Track.objects.create(album=album, **track_data) return album
● 自定义RelatedField
虽然上面说了三四种RelatedField基本上可以满足很多场景了。但是总还是有些场景无法满足,比如我想这个RelatedField形成的列表是目标对象类的其中的某几个(如果是一个的话用SlugRelatedField即可)字段的值以一定格式形成的字符串,此时就需要我们自己来实现一个RelatedField。常见的,我们在目录中创建一个fields.py文件,然后在里面写:
class TrackFormatField(serializers.RelatedField): def to_presentation(self, value): return 'Track %s: %s' % (value.order,value.title)
看到我们重载了to_presentation方法,这个方法控制的就是序列化器是以何种格式序列化输出信息的,它接受一个value参数,指的是被传入这个字段的那个对象,返回一个字符串。然后在AlbumSerializer里面就可以令
tracks = TrackFormatField(many=True),这样就使得最终出来JSON串中,tracks字段值的列表中每项的格式都是Track 1: xxx这样子。
● 通过重载serializers.Field自定义Field
上面讲的自定义RelatedField是针对一些有表外关联的字段序列化时可以用的办法。如果对于有些字段单纯只是想做一个翻译或者其他不涉及其他模型的处理,那么可以考虑重载Field这个更加底层的类。
继承Field类时,必须要进行重载的方法有to_presentation以及to_internal_value。两者分别是用来将Python对象转化为字符串以及字符串转化为Python对象的。下面给出一个例子
class EnvAdaptField(serializers.Field): def __init__(self,envDict,*args,**kwargs): self.envDict = {k:v for k,v in envDict} serializer.Field.__init__(self,*args,**kwargs) def to_presentation(self, value): return self.envDict.get(value,'未知'); def to_internal_value(self, data): return dataenv = [('0','生产'),('1','SIT'),('2','UAT')]# 在某个serializer中environment = EnvAdaptField(env)
首先不必这么死板,除了to_presentation和to_internal_value之外还可以重载一些其他方法。注意有时不是完全重写的话记得做一些类似于super的操作。比如这里重载了__init__方法之后使得自定义Field还可以接收一些额外的数据。从下面的env中不难能看出来,这个Field的目的在于将所属环境这样一个属性,用0,1,2等标识存储在数据库中,但是客户端获取数据时给的数据又要是生产,SIT等具体的文字描述。
to_presentation方法做到了把标识翻译成具体的文字。而to_internal_value的时候我们可以在前端做一些工作,比如select中的<option value="0">生产</option>,这样可以做到val()提交的时候本来提交的就是标识了,所以不做任何处理直接return 出来即可。
另外还有一些时候,可能需要在接受到一个请求之后,基于请求指向的那个对象做一些逻辑判断,对于逻辑不过关的请求做出拒绝回复。这应该怎么做?如果这个判断要放在field这个层面的话,那么在Field类中我们还可以重载另外一些方法比如get_attribute和get_value。这两个方法的作用分别是作为了to_presentation和to_internal_value的前处理方法。也就是说两个方法的返回分别是to_presentation和to_internal_value的参数。
对于上面的这个需求,我们可以这么干:
class empty: passclass AccountInUseField(serializer.Field): def get_value(self, dictionary): # 校验放在这个方法里做 for_sever = dictionary.get('for_server') request = self.context.get('request') tobe_in_use = dictionary.get(self.field_name, empty) if request.method in ('POST','GET','DELETE'): return tobe_in_use if [row[0] for row in Server.objects.get(id=for_server).accounts.values_list('in_use')].count(True) > 0 and tobe_in_use: # 一个服务器的账号最多只能有一个的in_use字段处于True状态 raise serailizer.ValidationError({ 'detail': 'In use account spotted'}) return tobe_in_use def to_internal_value(self,data): return data 这个类没写完整,在我的实践中(DjangoORM+restframework构造的RESTful标准API),通过API发出针对账号模型的请求时,就会通过这个类的代码。首先可以看到的是get_value方法接收了一个dictionary参数。其内容实际上是发来的所有请求参数的键值对。比如PUT请求就会把指向的这个模型的所有字段都给写出来,相对的PATCH请求可能就只会有一部分字段。self.field_name并不是由Field决定,而是在模型的serializer中通过调用Field类的Bind方法来决定的。比如在这个示例中self.field_name应该等于'in_use'。不写死成'in_use'也是考虑到了和源代码的一个适配性。同理,如果发来请求中没有in_use字段的话,dictionary中get也只能获得None,但是None对于一些输入输出标准来说是错误,源代码(rest_framework/fields.py文件中)定义了空类empty来代表空值而非None,这里也是模仿他。
再来看具体代码,self.context是Field类工作的上下文,是一个字典包含了view和request两个键。view的值自然就是请求由哪个视图处理,按照rest_framework标准,这个视图会关联一个serializer,而serializer中Bind了我们这个Field。request嘛自然就是这个请求本身了,获取到request之后我们就可以像在视图函数里获取request对象那样在这里也做类似的操作。比如通过request.method对请求方法做了一个过滤。如果是POST,GET,DELETE等方法,没必要做校验就直接返回掉。而PUT,PATCH等方法,由于是改数据,很可能会触及一个服务器账号只能有一个in_use是True的限制,所以要校验。校验条件涉及到我具体的模型设计,不多说了。总之当条件未通过时,我们raise了一个ValidationError,此时API就会知道本次请求失败了,从而返回失败的HTTP Response。默认情况下status_code是400。另外需注意ValidationError中的参数是一个字典不是一个简单字符串(虽然官方文档明明说简单字符串就行了。。)。另一种抛出错误的办法是self.fail方法。fail方法接受固定的几种错误模式作为Key比如fail('incorrect_type'),fail('incorrect_format')等,并给出了默认的信息,如果有需要也可以用。
最终如果通过了校验,没有raise起错误,那么就返回要修改的in_use值,给to_internal_value方法处理即可。
■ API的权限控制
通常API是需要有权限控制的。rest_framework给我们提供了大部分常见的权限模型,可以立即使用。但是说到权限控制,也是分成好多维度的。首先应该明确,控制的直接对象都是各种方法,即允许不允许某一个方法的执行。而控制的层级可以分成模型层面的和实例层面的。首先来说说前者。
● 模型层面的控制
模型层面的控制,只需要我们在视图类中直接添加即可。比如我们想对于Album这个模型做权限控制,将Album的两个视图类改写如下:
from rest_framework import permissionsclass AlbumList(generics.ListCreateAPIView): queryset = Album.objects.all() serializer_class = AlbumSerializer permission_classes = (permissions.IsAuthenticatedOrReadOnly,) def perform_create(self, serializer): serializer.save(owner=self.request.user)class AlbumDetail(generics.RetrieveUpdateDestroyAPIView) queryset = Album.objects.all() serializer_class = AlbumSerializer permission_classes = (permissions.IsAuthenticatedOrReadOnly,)
rest_framework框架自带的permissions类预定义了很多权限管控的模型,比如我们用到的IsAuthenticatedOrReadOnly就是指出了对于这个视图类包含的操作,要么只能读,涉及增删改操作的只能在当前用户通过验证的情况下进行。
● 对象层面的控制
对象层面的权限控制则稍微复杂一些。我们需要重新定义权限类的样子。我们可以在app中新建一个permissions.py文件。然后在这个permissions中自定义权限类。至于这个类怎么定义回头再说。首先我们要明白,对象层面上的权限控制,势必要求将我们编写的内容和django自带的用户模型(当然自己定义的用户模型的话就没必要了)关联起来。所以需要对Album模型做以下改动:
class Album(models.Model): id = models.AutoField(primary_key=True) album_name = models.CharField(max_length=80) artist = models.CharField(max_length=100) owner = models.ForeignKey('auth.User',related_name='albums',on_delete=models.CASCADE) def __unicode__(self): return ' %s' % self.album_name 通过一个外键,将django的用户和本模型联系起来。顺便,可以不特地from django.contrib.auth.models import User而直接使用字符串形式的'auth.User'。然后为了方便,我们干脆把整个数据库清空,重新录入数据。这里需要额外提一句,如果从admin界面进行Album新增的话,自然是可以选择owner是谁。但是如果通过API的PUT方法来新增,API目前还无法识别出owner是和当前用户关联在一起的。为了让API能够自动将发送请求的当前用户作为owner字段的值保存下来我们还需要做的一件事就是重载视图类中的perform_create方法。如:
class AlbumList(generics.ListCreateAPIView): ... def perform_create(self, serializer): serializer.save(owner=self.request.user)
注意在视图类中自带了属性self.request用于对请求中信息的提取(详情见前面我们从APIView开始继承时每个方法中有request参数这一点),perform_create大概就是这个类用于保存实例的方法。
好了,定义好了视图之后,再回头去编写我们需要的权限类。比如一个权限类可以这样写:
from rest_framework import permissionsclass IsOwnerOrReadOnly(permissions.BasePermission): def has_object_permission(self, request, view, obj): if request.method in permissions.SAFE_METHODS: return True return obj.owner == request.user
自定义的权限类继承自rest_framework内建的权限类permissions.BasePermission,在这个类中我们重载了has_object_permission方法,重载这个方法说明我们要做的是对象层面的权限控制。这个方法自带了request,view,obj三个参数,比较多的参数保证了我们可以实现非常灵活的对象层面权限控制。permissions.SAFE_METHODS其实就是('GET','HEAD','OPTION'),当请求的方法是这三个其中的一个的时候,性质都是只读的,不会对后台数据做出改变,所以可以放开,因此直接return True。当请求其他方法的时候,只有当相关对象的owner字段和当前请求的用户一致的时候才开放权限,否则拒绝。
我们还可以将SAFE_METHODS那条判断去掉,这样的话就是所有对非本人创建的,单个对象的访问都会被拒绝。
顺便一提,被拒绝时给出的json回复是{
"detail": "Authentication credentials were not provided."}(没有登录时)或者{ "detail": "You do not have permission to perform this action."}(登录用户非owner时)。最后一步,就是如何把这个自定义的权限类和实际的视图类结合起来了,其实和之前rest_framework自带的IsAuthenticatedOrReadOnly一样,将这个类赋予视图类的permission_classes属性中即可。
■ API的用户验证
与权限控制相辅相成的是验证工作。上面的权限控制的重要一个维度就是当前是否有有效用户登录,而这个就取决于用户验证工作了。从概念上来说,验证和权限控制应该分开来看,但是两者常常在一起用。
和权限体现在视图类的permissions_classes属性中类似的,验证体现在视图类的authentication_classes中,表明这个视图类涵盖的方法只认可这几种方式的验证,通过其他方式的验证的用户都视作没有验证;假如此时权限上对没有验证的用户有访问控制的话自然就访问不到了。
下面来看一下rest_framework自带的一些验证类
● TokenAuthentication
通过Token验证时B/S架构中常见的一种验证方式。其要义是用户先通过有效的账号和密码获取到一个token字符串,之后所有的请求只需要通过这个token作为一个标识,服务器认可token串就开放相关权限供客户端操作。rest_framework自带了一个rest_framework.autotoken的应用。我们可以通过它来较为简单地建立起一个token体系。
首先在settings.py的INSTALLED_APPS中假如rest_framework.autotoken应用。然后注意,这个应用定义了几个token相关的模型,所以要python manage.py migrate及时同步数据库。
接下来就是要构建一个带有token获取功能的url,这个url极其相关视图函数我们可以手动写,但rest_framework给我们提供了一些预设好的东西。比如:
from rest_framework.authtoken import views as token_views# 在url中加入: url(r'^api-token-auth/',token_views.obtain_auth_token)
如此,通过POST方法访问api-token-auth路径,并且带上POST参数{username:'xxx', password: 'xxx'},如果账号密码正确,就会返回一个token字符串了。
那么得到了这个Token之后怎么样才能把它用于实际请求中呢?只要在头信息中加上两条额外的记录,比如通过python的requests模块发起请求的话就像下面这样:
#!/usr/bin/env python# -*- coding:utf-8 -*-import requestsheaders = { 'WWW-Authenticate': 'Token', 'Authorization': 'Token 506c12a0fc447918957ab7198edb7adae7f95f84'}res = requests.get('http://localhost:8000/albums/',headers=headers)print res.status_codeprint res.content
需要注意的是,Authorization字段的值不仅仅是Token字符串,还包括了'Token '(最后带一个空格),当头信息中带有这样的记录,再访问authentication_classes中有TokenAuthentication的视图类时,就可以正常得到数据了。
当一个视图类中只有TokenAuthentication时,rest_framework提供给我们调试用的页面是无法正常工作的,因为那个页面上无论请求html或json,其请求的头信息中都不会有Authrorization这个字段。即使有值也不是Token xxx形式。所以为了这个页面正常工作(同时有时候会需要向网站内部用户提供访问,只要当前访问用户是有效用户就可以在页面上做一些增删查改操作,而这个操作就可以是调用API的动作),我们应该在有TokenAuthentication类的视图类中也加上SessionAuthentication这个类,确保比较友好的调用特性。
● SessionAuthentication
这种验证法基于django自带的会话机制。比较好理解,即一个会话只要通过了验证,那么这个会话就可以发起一些带有权限控制操作的请求了。
另外由于django层面上的要求,当发起PUT,POST,DELETE等方法的请求时会要求请求带有csrf_token字段的信息。然而这个csrftoken在这里就是一个比较tricky的东西了。
是这样的:当我们指出多种认证机制的时候(比如SessionAuthentication和TokenAuthentication共用时),我们知道SessionAuthentication是要求服务端发出一个token给客户端作为应用的,然而TokenAuthentication的场合并不需要,所以此时在发起请求时必须指出:“我的请求是要通过SessionAuthentication类来验证的”(反过来,当我们的请求要通过TokenAuthentication来验证的时候也要在请求中指出,这个在上面提到了),否则服务端将不获取请求中的token信息,这就会导致在发起不安全请求如POST,PUT,PATCH等的时候报错:{"detail":"CSRF token not found"}之类的错误。
解决办法:和TokenAuthentication类似,我们在请求的header中添加一个字段的信息:X-CSRFTOKEN即可。不过请注意,这个字段的值并不是我们为了泛泛解决django中POST之类请求需要csrftoken时,添加的ajax全局参数csrfmiddlewaretoken,而应该是一个保存在本地cookie中的一个csrftoken(因为Session的本质就是通过cookie实现的)。这也是我对比了API调试界面发起的请求和在自己开发的页面上发起请求不同得出的结果。具体来说,我们只要在发起的ajax请求中添加如下:
function getCookie(key){ // 这个函数是为了方便取cookie值而写的 var cookie = document.cookie; var kvs = cookie.split(';'); var i = 0; while (i < kvs.length){ var kv = kvs[i].split('='); if (kv[0] == key){ return kv[1]; } i++; } return null;}$.ajax({//发起ajax请求,其他参数省略 headers: { 'X-CSRFTOKEN': getCookie('csrftoken') //因为有'-'在里面,所以X-CSRFTOKEN必须有引号引起来 }}) 这样就不会报错啦!
● 自定义验证类
和自定义权限类(上面实现对象层面的权限控制时提到的)一样,验证类也可以自己定义。这个类需要继承自BaseAuthentication
然后这个类要实现authenticate方法。在这个方法中实现验证的逻辑,当用户没有给出验证信息时应该返回None,当用户给出错误的验证信息时抛出AuthenticationFailed错误,当用户验证成功时返回一个元组:(user,auth),user是通过验证的用户对象,auth则是验证用的关键信息。比如可以参考下TokenAuthentication这个类的实现,看下源码就会明白了。
除此之外,我们还可以重载authenticate_header方法,这个方法接受request作为参数,并且返回一个字符串。当用户没有提供有效的验证信息,服务端返回401错误时,这个字符串会被包含在回应的头信息的WWW-authenticate字段中,提示用户提供何种验证信息。
下面来具体实现一个类,这个类规定的验证方式很简单粗暴,就是要求请求头信息中带有用户名,只要用户名存在在我们的系统中就算通过认证。这样的:
from rest_framework import authenticationfrom rest_framework import exceptionsfrom django.contrib.auth.models import Userclass UsernameAuthentication(authentication.BaseAuthentication): def authenticate(self,request): username = request.META.get('X-USERNAME') if not username: return None try: user = User.objects.get(username__exact=username) except User.DoesNotExist: return exceptions.AuthenticationFailed('No Such User') return user,username
哦对了,这部分代码可以类比权限类,重新建一个authentications.py文件来存放。
包含这个权限类的视图类,访问时需要在头信息中加入X-USERNAME的信息。顺便一提,用python的requests库加入头信息时会发生一个神奇的事情,我设置的明明是X_USERNAME,但是实际发出的头信息中字段名却变成了HTTP_X_USERNAME...,需要注意。
■ 过滤
至此,我们的API已经有了较为完备的功能,但是实际使用还是不行的,因为它只能傻傻地返回一个模型的所有记录or指定的单个记录。实际上,API通常会允许请求中包含一些所谓的过滤参数,来把整个结果集进行缩圈、排序,从而得到一个更加漂亮干净的数据集合。
rest_framework框架整合了django-filters这个django组件,通过它可以很方便地实现具有足够用过滤功能的API。
首先要保证django-filters已经正确安装了,pip install django-filter(注意没有s,否则会装上另一个模块的)即可。另外在settings.py的INSTALLED_APPS中也要包含上django-filters。(这步不要忘。。否则会在后续的访问过程中报找不到django-filters相关的模板)。另外,通过django-filters和rest_framework合作做出来的过滤器都是通过GET方法加上一定的参数请求特定的API的url,来获取一个有限的结果集的。
接着找到我们要进行过滤的一个视图类,这个类通常是那种返回整个结果集的,也就是说是ListAPIView继承出来的那种视图类。如果想要给Detail的视图类增加一个过滤器,不是不可以,但是意义不大(毕竟url已经帮你缩圈到只有一个对象了),而Detail类视图过滤器的条件若是和当前对象不符合的话就会爆出404错误。综上,接下来的所有说明都基于一个完整结果集的那种视图类,比如AlbumList这个类,我们改成这样:
# 在views.py文件中 #from rest_framework import genericsfrom rest_framework.permissions import IsAuthenticatedfrom rest_framework.authentications import SessionAuthenticationfrom models import Albumfrom serializers import AlbumSerializerfrom django_filters.rest_framework import DjangoFilterBackendfrom rest_framework.filters import OrderingFilterclass AlbumList(generics.ListCreateAPIView): queryset = Album.objects.all() serializer_class = AlbumSerializer permission_classes = (IsAuthenticated,) authentication_classes = (SessionAuthentication,) #下面几行是新的 filter_backends = (DjangoFilterBackend,OrderingFilter) filter_class = AlbumFilter ordering_fields = ('artist',)
首先在视图类中我们引入了filter_backends属性,指定这个属性的值中有DjangoFilterBackend,相当于是把rest_framework和django-filters两个组件联系了起来。OrderingFilter来自rest_framework.filters而非django-filters下面的某个包(切记切记,为了找这个浪费好多时间。。),把它也加入filter_backends是为了让这个视图类可以支持排序。说到排序,ordering_fields指出了这个API的排序可以指定哪些字段作为排序基准。调用时加入ordering参数可以拿来排序,像这样:ordering=-artist(以artist为字段desc排序),ordering=artist,album_name(以artist和album_name两个字段asc排序)。
另外,没有在上面的代码中写出来的是,可以添加一个ordering属性来指定默认的排序基准,比如ordering = ('artist',) 就是指默认情况下以artist字段做升序排序,不带任何参数请求时返回结果的排序就是这样的。
然后再来看重头戏,AlbumFilter是一个Filter类,是我们自己实现的,它指出了这个API装的过滤器支持哪些字段的什么样的过滤。AlbumFilter这个类我们放在了同目录下的filters.py文件中,这么写:
from django_filters import FilterSetfrom models import Albumclass AlbumFilter(FilterSet): class Meta: model = Album fields = { 'album_name': ['exact','contains'], 'artist': ['exact','contains'], 'tracks__title': ['exact'], } 还是很好懂的,Meta中的model指出了这个过滤器是给哪个模型用的,fields指出了该模型各个字段都支持怎么样的过滤方法,遵循djangoORM的规则。字段应该和给出的模型对应,如果有该模型没有的字段则会报错。另外强大的是可以做关系查询,即tracks__title表明在API的过滤器中我们可以进行关系的查询了! 各个字段的值是一个列表,指出了匹配规则,很好理解就不说了。对于数字类型等也可以加入lt,gt等规则。
构建了这样一个视图类之后,再访问我们的API调试界面,可以看到会多出一个Filter的按钮供我们调试过滤器,按下按钮弹出的界面是各种条件(包括过滤和排序等),尝试着写一个过滤一下,观察下URL规则吧。其实和django中是一样的。比如一个uri可能是:/albums/?album_name__contains=肖邦&artist__contains=杰伦&ordering=-artist,这就把整个Album.objects.all()结果集缩圈到album_name字段中有“肖邦”二字,且artist值含有杰伦的结果集,并且给出的结果集按照artist字段的值降序排序。
● 关于filter和serializer之间的独立性
在使用了一段时间的rest_framework框架之后,对这个方面有些认识了。在ORM设计性比较强的应用中,我们可以直接继承ModelSerializer这个类来方便地基于一个模型创建出一个序列器类。另一方面,也可以继承FilterSet,方便地基于一个模型来创建一个过滤器类。而后这个过滤器类往往还要被当做成一个属性赋予序列器类。也就是说这里面的serializer和filter两个关联起来了。在这个过程中,可以注意到,serializer和filter都基于了同一个模型所以总是下意识地觉得,filter定义的字段必须是和serializer相同或者是其一个子集。其实不然。两者是互相独立的。
比如在serializer中我们可以在class Meta中写出fields = "__all__",此时序列器类会自动读取模型的所有字段并且基于此创建序列器。对于某些字段如外键或者要做一些额外处理的,我们可以在Meta前面写上某个字段=某个Field来做特别处理。
在filter中,定义的字段则是相对自由的。比如一般filter中会指定model=xxx,然后后面的fields其实除了serializer里面定义的那些字段之外,还可以写一些符合逻辑但是没有被包括进的字段。这些字段就可以在rest_framework构成的API中直接使用而不出错的。比如filter的fields中指定for_client__clientno: ['exact']这样一个字段。很明显for_client是另一个模型的外键,而for_client__clientno可以经过一次外键关联碰到那个模型的clientno字段。
● 重载初始结果集
上面的视图类中明确指出了queryset=Album.objects.all(),也就是整个结果集。但是有时候我们可能希望,可以根据请求上下文在过滤之前的就进行一次“预过滤”,这可以通过重载视图类的get_queryset方法实现。比如不知道是否还记得,之前为了测试对象层面的权限控制,我们为Album增加了一个owner字段并连接到了User模型上。其实这个权限也可以在这里通过重载初始结果集的办法来实现:
def get_queryset(self): user = self.request.user return user.albums.all()
这样子的话,比如我是admin登录进来的,不论我怎么过滤,最多也只能看到owner是admin的Album对象而不会越界看到其他用户的。
■ 分页
有了过滤,分页自然也是不能少的。我们可以通过重载视图类的pagination_class属性来指定一个分页类实现分页。分页类可以用rest_framework已经预设好的一些类也可以自己实现。
分页分成很多种风格,首先来说下rest_framework为我们预设好的一些风格的分页方式。比如:
● LimitOffsetPagination
rest_framework.pagination.LimitOffsetPagination这个分页类帮助实现的是类似于Mysql中limit和offset方式的分页。在API请求参数中加上GET参数limit=X&offset=Y的话,就可以把当前结果集缩圈成第Y+1个到第Y+X个的那X个结果。比如我们直接将其应用到某个ListAPIView中:
from rest_framework.pagination import LimitOffsetPaginationfrom rest_framework import genericsclass ServerList(generics.ListCreateAPIView): queryset = Server.objects.all() serializer_class = ServerSerializer permission_classes = (IsAuthenticatedOrReadOnly,) authentication_classes = (SessionAuthentication,TokenAuthentication) filter_backends = (DjangoFilterBackend,OrderingFilter) filter_class = ServerFilter #设置pagination pagination_class = LimitOffsetPagination ordering = ('for_client__clientno',)
此时我们访问ServerList.as_view关联的那个url时可以加上limit和offset的参数了。顺便,在rest_framework的可视化调试界面上,带有分页地访问时会出现一个分页按钮,可以点击不同的页码跳到不同的页。而且分页比较智能,挺好用的。
需要注意的是,加入pagination_class之后,当请求带有分页参数limit时这个类的返回不再是单纯的[{...},{...}]这种形式的JSON了。而是类似下面这种:
{ "count": 5, "previous": "xxx", "next": "yyy", "results": [ {...}, {...} ]}
previous和next的值其实是两个url,分别指出当前分页的上一页和下一页的请求url,非常贴心!results即这次请求得到的结果,count是指在未分页时结果集的总长度。
有些时候组件发出的请求自带了limit(比如bootstrap-table在设置了pagination:true之后)参数,此时应该注意到返回结果的变化。
● PageNumberPagination
■ 去除web调试界面
在完成API的编写之后,上生产环境之前,应该把web的调试界面去除。虽然通过ajax发起的请求可以指定dataType参数为json而不为html,从而避免返回API调试界面html的问题,但是依然可能会存在比如表单提交,其他请求等场景下返回了html的情况。为了一劳永逸地禁用web调试界面,应该在settings.py中加入如下配置:
REST_FRAMEWORK = { 'DEFAULT_RENDERER_CLASSES': ( 'rest_framework.renderers.JSONRenderer', #'rest_framework.renderers.BrowsableAPIRenderer' 这个就是调试界面的renderer )}
只要指出我们不要BrowsableAPIRenderer这个renderer那么就可以让所有请求得到的都是JSON格式的数据了。
■ 零散
● patch等方法总是无法如愿修改?
按照JSON传输的标准,检查ajax请求参数是否包含了下面几项:
traditional: true,
contentType: 'application/json; charset=utf-8'
以及data字段的object应该有JSON.stringify()包裹,如data: JSON.stringify({xxx})
同时检查上面提到过的验证字段如headers中应当添加{'X-CSRFTOKEN': getCookie('csrftoken')}这样的
● 关于rest_framework有多层外键时取数据的原则
在通过rest_framework构建API的时候,对于List型的API(且不加任何filter参数条件)给出的数据,印象中感觉就像是select * from xxx这样的。但其实rest_framework会对DB中实际存储的数据,根据ORM的规则判断来进行一个“预过滤”。即不符合ORM逻辑的数据rest_framework并不会给予展示,即便数据真实存在于DB中。
比如针对如下这个模型:
class A(models.Model): for_B = models.ForeignKey( B, on_delete=models.CASCADE, related_name='has_A' ) # ...
由于某个B对象被删除后所有相关的B.has_A.all()中的A对象都会被一并删除,所以如果正确地按照ORM的逻辑来,A表里应该是不会存在某个记录,其for_B_id字段的值在B表中不存在记录。但是数据库并未对这个逻辑做出限制。加入我们在A表中插入一条INSERT INTO A VALUES(.....,'999'),即for_B_id是999的记录。如果B表中存在某个B对象的id是999还好说,如果没有,那么这个A记录就不会在通过rest_framework获取A列表时出现。此时就会导致API获得的数据条数和实际表中的记录条数不一致。
这一层控制是在rest_framework而不是ORM本身中做出的,因为对于这种记录,如果在代码中进行A.objects.all()的话还是会被选择出来的。
反过来,如果在模型定义中就设置了on_delete=models.SET_NULL,null=True的话,那么手动插入这么一条记录后,rest_framework在获取所有A对象的时候会给出这条记录,并且其for_B字段的值是null